

Francesco di Lardo
Mitglieder
-
Beigetreten
-
Letzter Besuch
Alle Inhalte erstellt von Francesco di Lardo
-
Ich bin mir nicht sicher, glaube jedoch, daß man bei den "brauchbarsten" und bekanntesten Tools um eine Registrierung nicht herumkommt. Du kannst natürlich zu dem Zweck eine Wegwerf-Emailadresse mit Phantasiedaten einrichten (was Deine Spuren im Netz dennoch nicht anonym macht). Es gibt auch Services für "one-use" Email-Adressen, die man nur ein einziges Mal verwendet - in diesem Zusammenhang also etwa bei jedem einzelnen Login bei dem Dienst eine andere. Letzteres hat natürlich den Nachteil, daß Du innerhalb des Tools auch jedesmal bei Null anfängst. Teilweise filtern die Tools aber derartige Email-Provider heraus. D.h. eine Registrierung scheitert dann. Ich denke, wenn Du halbwegs wenig Deiner Daten umherschleudern willst, dann legst Du Dir eine neue Email-Adresse mit Phantasiedaten für den Zweck an, nutzt ein VPN und achtest auf die einschlägigen Browser- System- und Tooleinstellungen. Der Haken kommt natürlich dann, sobald Geld bezahlt wird. Die Tools sind ja oft so designt, daß man zwar "umsonst" ausprobieren kann, dann aber nur so wenige Tokens, Versuche, Zeit, whatever bekommt, daß das Herumspielen lästig ist. Exakt so lästig, daß man sich eben doch dazu hinreißen läßt, ein paar Euro oder Dollar im Monat zu bezahlen (selbstverständlich nicht automatisch verlängernd und zum Monatsende einfach kündbar) hinreißen läßt. Wenn Du bezahlst, hast Du natürlich die Verbindung Deiner Phantasie-Emailadresse mit einem Ort, wo "echtes" Geld herkommt. Und wo "echtes" Geld herkommt, sind eben auch "echte" persönliche Daten dahinter irgendwo. Was so Dinge wie Steam o.ä. angeht, wofür an der Supermarktkasse die ganzen Karten zu erwerben sind: Zahlst Du eine solche mit Bargeld, kämest Du nebst den zuvor beschriebenen Maßnahmen womöglich tatsächlich an anonyme In-App Käufe. Ich bezweifle aber, daß es so etwas wie Pre-Paid Guthaben an der Supermarktkasse für PayPal gibt (ist mir zumindest nicht aufgefallen). Gäbe es sowas, dann wäre dies evtl. ein mehr oder minder anonymer Ansatz jenseits des "Free Trials" bei Musik-Apps. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in Neue Charakterbögen und SpielhilfenWolltest Du hier wirklich die Grenzen heruskitzeln, was noch "legit" ist und was nicht mehr, dann müßtest Du wohl den Fachanwalt fragen. Was Dich freilich noch immer nicht notwendigerweise dafür schützen würde, daß ein anderer Fachanwalt, insbesondere einer von z.B. Wizards of the Coast oder einer Firma mit Geld im Nacken anderer Ansicht ist. Einschließlich der Möglichkeit, daß Du vielleicht darauf verzichtest, Deine (nehmen wir einfach mal an objektiv begründet richtige) Position durchzufechten wegen der Mühe und des Prozeßrisikos. Ich glaube, es wäre ebensowenig hilfreich, bis krass hart an die Grenze herauszukitzeln, was gerade noch nicht "gleich genug" ist, um rechtlichen Anstoß zu erwecken, wie auch sich stattdessen entgegengesetzt auf "völliges Generischsein" zurückzuziehen. Wir stellen ja durch die schlichte parallele Existenz einer vielzahl von Rollenspiel-Systemen fest, daß es da immer wieder Ähnlichkeiten zwischen den Systemen gibt, die teils gar in Punkten frappierend sein mögen. Ich denke nicht ohne Schmunzeln daran, daß einige Leute geschrieben haben, das neue Damatu D1 erinnere sie in Teilen deutlich an D&D (wobei ich mir dazu kein Urteil erlaube). Wären diese systemischen Ähnlichkeiten, die wir in diversen Systemen haben, wirklich allgemein rechtlich relevant, so könnten wir wohl davon ausgehen, daß die entsprechenden Firmen sich in den letzten Jahrzehnten im Zweifel gegenseitig totgeklagt hätten. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in Neue Charakterbögen und SpielhilfenJa. Wenn da nichts "offen Erlaubtes" vorliegt, oder es gar "offen verboten" ist, kann man nicht von Erlaubnis ausgehen. Ich glaube, es gab auch in der D&D Community ziemlichen Aufruhr als Wizards of the Coast versucht hat, beim neuen D&D 5.5e (oder D&D 2024 - wie man es auch nennen will) an den betreffenden Lizenzen herumzudrehen. Auch wenn Dinge absolut verboten sind, würde ich aber gerade bei der Breite der D&D Community davon ausgehen, daß irgendwelche Leute dann eben einen nahezu "nackten" Charakterbogen bauen würden und mehr ins "inoffizielle/illegale" Load-File reinpacken o.ä. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensEben. Und auf diesen Artikel hat @Prados Karwan in seiner Argumentation auch maßgeblich verwiesen. Und Rainer Nagel, der den Artikel in Hexenzauber & Druidenkraft verfaßt hat, ist schließlich auch nicht irgendwer. Es gibt also in der Tat nicht nur solide Gründe, sondern auch sehr namhafte Vertreter für diese Ansicht, die ich im übrigen teile - auch nachdem ich den Artikel eben in meinem Exemplar noch einmal gelesen habe. Aber es kommt eben auf den Spielleiter an. Es gibt in der Tat wenige, die den Standpunkt der "totalen" Fernsteuerung vertreten. Aber namhafte Vertreter billigen schon weitreichende Kontrolle zu mit folgenden wichtigen - und sinnvollen - Einschränkungen: Gewisse a) Ablenkungen sind nicht ausgeschlossen (was aber nicht heißt, daß sie ständig vorhanden sein müssen). b) Der Vertraute wird nicht wider seine eigene Natur handeln, d.h. eine "vertraute" Maus käme nicht auf die Idee, eine Katze anzugreifen, auch wenn ihr Herr und Meister dies gern hätte. Im Falle der Einschränkungen, also bei vorhandenen Ablenkungen oder gewünschtem Verhalten wider die Tiernatur, wären dann aus meiner Sicht zusätliche Anforderungen gefragt und gerechtfertigt, wenn der Zauberer solches Handeln des Tieres "durchsetzen" will. Aber auch nur dann. Auf diese Weise wird dann meiner Ansicht nach ein Schuh aus der ganzen Sache und sie wird mit einem ausgewogenen Kosten-/Nutzenverhältnis spielbar. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensJa. Auf den Seiten 16 - 21 im Rahmen der ausführlichen Beschreibung der Fertigkeit "Abrichten". Beziehe ich dies aber auf einen Level 1 Hexer (in Startkonfiguration), der einen Raben als Vertrauten hat, so bedeutet dies folgendes: Abrichten kann ein Hexer zu Spielbeginn gar nicht lernen, weil im Bereich "Freiland" überhaupt keine LE zur Verfügung stehen. Dies hätte dann zur Folge, wollte man einen zu Spielbeginn bereits "gebundenen Vertrauten" mit der später erworbenen Fertigkeit "abrichten", müßte man hierfür erst einmal die Zeit aufwenden - während des Abenteuerns. Ein Rabe zählt sicher nicht zu den "domestizierten Haustieren", also müßte der "vertraute" Rabe erst einmal "gebändigt" werden. Was mit Abrichten +8 für das Tier auch schon mal endgültig fehlschlagen kann nach den möglichen Versuchen. Danach muß man den Raben "ausbilden", was abermals bei diesem Wert ebenso in etwa einem Drittel der Fälle final fehlschlägt. Erst dann kann ich beginnen, einzelne Tricks beizubringen. Wenn ich das nicht beim zweiten Versuch schaffe, muß ich erst "Abrichten" (nicht billig!) steigern, bevor ich es nochmal versuchen kann mit dem spezifischen Trick. Kritische Fehler während der Kette sind nochmal schlimmer. Im Mysterium (M5) steht unter "Greifvögeln" auch, daß ein abgerichteter Vogel als Kundschafter eingesetzt werden kann, wenn ein Zauberer ihn mit "Tiersprache" ausfragen kann - wobei die Resultate wegen der tierischen Intelligenz aber nur vage bleiben. Es kommt also - sofern der Spielleiter "Abrichten" und "Tiersprache" neben "Binden des Vertauten" fordert, selbst bei sehr großem, risikoreichen, aber angenommen erfolgreichen Aufwand bestenfalls überschaubar viel hinaus. In der Konfiguration trägt das "Modell" in meinen Augen nicht nur zu Beginn der Charakterentwicklung nicht, sondern später ebensowenig - es sei denn, man bewegt sich in so hohen Levelspähren, daß sowieso alles egal ist. Francesco di Lardo
-
Ich glaube, die Charaktere sind womöglich auch ein wenig die Spiegel der Spielerschaft. In unserer heutigen Wohlstandswelt in Deutschland wird halt viel mehr Aufhebens um Haustiere im Sinne von "Schoß- und Streicheltieren" gemacht, als etwa in ärmeren Regionen der Welt, wo es in erster Linie darauf ankommt, Nutzen und Nahrung aus den Tieren zu ziehen. Ebenso wie auch bei uns in Deutschland diese Aspekte vor nicht langer Zeit noch vielmehr im Fokus standen. Ich will es mal so sagen: Zu Zeiten meines Urgroßvaters konnte man vermutlich kein "Katzenfutter" kaufen. Als ich Kind war, schon. Allerdings gab's zu meiner Kindheit noch kein "Sheba senior - für die ältere Katze". Ebenso war es vor nicht allzulanger Zeit auch nicht ungewöhlich, daß man einen Kanninchenstall hatte und die Kinder die Tiere so liebgehabt haben und gestreichelt wie heute. Beim nächsten Fest war aber trotzdem dann eins im Kochtopf und aus dem Fell hat man irgendwas Nützliches gemacht. Dürfte heute seltener vorkommen. Auch wenn das nachfolgende Beispiel zugegebener Weise an den Haaren herbeigezogen ist: Ich glaube, daß ein afghanischer Hirte, der Midgard spielen würde, für seinen Charakter nicht auf die Idee kommen würde, einen Gnadenhof für alternde tierische Vertraute einzurichten. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in Neue Charakterbögen und SpielhilfenIm Detail sicherlich. Ich glaube, um zum Schluß zu kommen, daß es generische Mechanismen gibt, die in unterschiedlichen Rollenspielen ihre Anwendung finden, braucht man keinen. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in Neue Charakterbögen und SpielhilfenSo habe ich's gesehen für D&D 5e. Die Basis-Regeln sind dafür öffentlich im Netz seitens des Herstellers. Weil D&D nun mal enorm verbreitet ist, gibt es allgemein auch eine enorme Menge an Zeug, die Leute dafür gebaut haben. Darunter unendlich viele mehr oder minder automatische Characterbögen. Ein sehr gute Variante davon hat die "öffentlichen" Regeln davon per default mit drin. Für so ziemlich alle denkbaren Erweiterungen gab es diese Load-Files, wo alles drin war, bis zum letzten individuellen magischen Gegenstand, was dann die Drop-Down Menüs des Charakterbogens entsprechend erweiterte. Die Load-files sind, ganz klar, natürlich nicht "offiziell". Diese privat für sich zu erstellen und zu nutzen, dürfte das Problem nicht sein. Klar gilt das nicht fürs "öffentlich zugänglich" machen. Im Gegensatz zu Midgard hat D&D natürlich eine ganz andere kritische Masse. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in Neue Charakterbögen und SpielhilfenIn Rollenspielen kommen rassenspezifische oder noch eher klassenspezifische Lernkosten immer wieder vor. Diese Art Mechanismen halte ich für generisch. Anno Dunnemals habe ich für RMSS (Rolemaster Standard System) mal eine Excel-Lösung zum Lernen gebaut. Bei Rolemaster gab's zu dem Zeitpunkt etwa 260 Fertigkeiten in 55 unterschiedlichen Fertigkeitskategorien. Die Kosten für die Fertigkeiten und Kategorien variierten je nach Charakterklasse. Bei Midgard gibt es auch diese Art Mechanismen. "Leiteigenschaften" für Fertigkeiten gibt's in Midgard, Rolemaster, D&D und auch anderswo. Bestimmte Rassen bekamen +X (oder auch -X) auf gewisse "Basiseigenschaften" (die bei RMSS selbstredend anders heißen) wie in Midgard Gnome, Elben oder Zwerge auch. Für ebenso generisch halte ich, was die einen "Backgrounds" (D&D) nennen, die anderen z.B. "Training Packages" (RMSS), wo es dann bestimmte Sets and Fertigkeiten oder Besonderheiten gibt. Das Konzept der "Modifikatoren" auf Manöver kommt auch ständig vor, à la "leicht" +10, "mittel" +0, "schwer" -10. Francesco di Lardo
-
Zeigt sehr illustrativ, welchen Umgang mit der Thematik Pegasus für "richtig" hält. Dem kann ich nur beipflichten - traurig: M1-5 ist nicht mehr, irgendwann kommt dann wohl D1. Francesco di Lardo
-
Natürlich ganz Deine Entscheidung für Deinen Charakter. Halte ich aber allgemein für überhaupt nicht überzeugend. Gerade Charaktere, die naturaffin sind (und daher evtl. besonders häufig mit der "Vertrauten" Thematik befaßt), sind sich bewußt, daß Sterben Teil der Natur ist. Weniger naturaffine Charaktere dürften das eher noch prosaischer sehen. Wieviele Mäuse hat die "vertraute" Katze gefressen in ihrem Leben? Es ist nun mal so, daß die Mücke, die in die Kerze fliegt, tot ist. Hat nichts mit Gerechtigkeit zu tun, das ist nun einmal der Gang der Dinge. Warum ein Charakter, der 20 Jahre lang auf Abenteuer war und dabei vermutlich Dutzende, wenn nicht weit mehr, Menschen, Humanoide und sonstige Tiere und Kreaturen umgebracht hat, nun ausgerechnet wegen seiner altersschwach gewordenen Katze so ergriffen ist, daß er fortan "sein altes Leben" an den Nagel hängt, erschließt sich mir nicht. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensWas die Thematik Wahl von "Binden des Vertrauten" bei Charaktererschaffung angeht: - Zwischen der Interpretation des Spruches gibt es himmelweite Unterschiede zwischen den beiden Polen des Meinungsbildes. - Die Spruchbeschreibung selbst ist ungenau und läßt Fragen offen. - Es gibt für M5 keine "ultimative Stelle" für Regelfragen mehr. @Prados Karwan hat diese niedergelegt. Allerdings hat er seine wohlbegründete Position vor Jahren mit Blick auf "Binden des Vertrauten", gar noch prä M5, deutlich dargestellt. - Fazit: Es hängt (nur) vom eigenen Spielleiter ab. Und in dem Zusammenhang ist man wirklich gut beraten, diese Frage vorab mit dem eigenen Spielleiter zu klären: Ist dessen Interpretation des Spruches "eng", dann würde ich davon abraten. Ohne auch nur auf die Risiken näher einzugehen, wenn ein kaum kontrollierbarer Vertrauter laut Spruchbeschreibung seinen Herren im Falle eines Angriffs auf diesen "nach Kräften verteidigen wird" und alle Unwägbarkeiten zu beleuchten, die sich im Zusammenhang mit zusätzlichen "Anforderungen" ergeben. Fordert der Spielleiter zusätzliche Fertigkeiten und Sprüche zur besseren Kontrolle ein, wie etwa "Abrichten" und "Tiersprache", führt es die Sache allein aufgrund der Kosten dafür ad absurdum. Die Fertigkeit "Abrichten" kostet den Hexer 240 EP & 800 GS, der Spruch "Tiersprache" 1350 EP & 1500 GS. Um das zu "bezahlen", müßte man erst einmal Mitte Grad 8 erreichen - und dabei bis dahin auf das Lernen von ALLEM anderen verzichten. Illusorisch. Ist die Interpretation eher "weit", wie seinerzeit in den Threads zum Thema von @Prados Karwan vertreten (der ich im wesentlichen beipflichte), dann wäre "Binden des Vertrauten" für einen Zauber bei Charaktererschaffung eine gute Wahl. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensVöllig richtig. Im LARP geschieht dies z.B. naturgemäß "ohne Würfel" - ist mir ganz und gar nicht fremd. In den Kampagnen, die ich geleitet habe, mußten die Spieler grundsätzlich alle sozialen Fertigkeiten ausspielen, auch wenn sie Fertigkeiten dazu besaßen. Das "Endresultat" habe ich danach bemessen, was beim Ausspielen und Wurf zusammen so herauskam: Wenn jemand wirklich inspiriert, schlagfertig und clever gespielt hat, dann konnte dies auch über einen mäßigen Wurf hinweghelfen. Sofern die Spielsituation wichtig war, jemand lieblos ausgespielt hat, dann konnte auch ein guter Würfelwurf nur bis zu einem gewissen Grad weiterhelfen. Bei wenig schwerwiegenden Situationen, wo ein ausführliches Ausspielen mehr Zeit kostet, als es spieltechischen Mehrwert hat (z.B. Handeln auf dem Markt), habe ich es dann auch gern beim Würfeln bewenden lassen. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensSchon klar - bin ja bereits seit über 35 Jahren "im Geschäft"... Francesco di Lardo

-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensDem stimme ich zu. Da der Hintergrund des Charakters "Adel" ist, dachte ich mir, ich sollte erstmal "Etikette" und dann "Gassenwissen" lernen. Anfangs ist die Umgebung auch wohl eher ländlich. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensHatte den Spielleiter gefragt - sieht er auch so. Soweit so gut. Er meint jedoch, einen "Fernsteuerung" des Vertrauten sei nicht möglich, dafür brauche man dann "Tiersprache", "Abrichten" oder so Dinge. Offen gestanden kann ich mich nicht mehr genau erinnern, wie dies damals bei einem Hexer in unserer Spielergruppe (der nicht mein Charakter war) vor Jahrzehnten lief. Aus anderen Rollenspielsystemen (Rolemaster, D&D) kenne ich es so, daß dort die Familiars/Vertrauten "fernsteuerbar" sind, weshalb ich dies für Midgard einfach auch so angenommen hatte, ohne etwas zu hinterfragen. Wie wird dies also in Midgard gehandhabt? Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensIn dem Zusammenhang stellt sich die Frage, wie genau die Opfer den Zusammenhang herstellen können. Bei D&D gibt es ein paar Sprüche, bei denen explizit in der Beschreibung steht, daß die Opfer die Bezauberung bemerken und dem Zauberer im Anschluß "feindlich" gegenüberstehen. Wie steht es dann bei M5 und Sprüchen wie "Anziehen" - wird dies überhaupt als Zauber oder eher als impulsives eigenes Verhalten wahrgenommen? Abgesehen von kritischen Fehlern oder Unachsamkeit des Zauberers würde ich eher letzeres annehmen. Käme so etwas bei demselben Opfer im Zusammenhang mit demselben Zauberer allerdings häufiger vor, dann könnte das Opfer eher ins "Überlegen" kommen. Zumindest das Regelwerk scheint hier nicht explizit zu werden. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des Lernens"Sehen in der Dunkelheit" steht weit oben auf der Liste. Zum einen, wie Du sagst, um sich geschickter verdrücken zu können. Und auch, um in Dunkelheit Ziele ausmachen zu können - oder solche, die unsichbar sind. Wasseratmen und Hitzeschutz sind glaube ich anfangs ein wenig zu situationsgebunden. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensGuter Punkt! Danke. Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensBeeinflussen geht in M5 zum Beginn nicht. Sicher ein guter Kandidat - hatte vor ewigen Zeiten mein M4 Magier auch stets gern genutzt. "Etikette" wäre die Alternative zu "Verstellen" gewesen. Bei "Verstellen" ist in M5 auch "Verkleiden" und "Stimmen nachahmen" drin, was bei M4 separat war. "Etikette" deckt dagegen in M5 auch "Tanzen" und "Brettspiele" (in gehobenen Kreisen) mit ab. Gerade, da als Sozialer Stand "Adel" gewürfelt wurde, steht "Etikette" aber mit als nächstes für die Zukunft an. Bei meinem Charakter ist Au leider nur 25. Da muß es eben Charisma und Persönlichkeit richten. Ansonsten dachte ich mir: "Think big!" 😁 Die +6 auf EW:Verführen von "Anziehen" wiegen dabei die -6 für "Opfer hat festen Partner und Charakter / soziales Umfeld begünstigt Treue" auf. Alternative zum Spruch "Anziehen" hätte "Besänftigen" sein können - dabei erschien mir ersteres aber nützlicher. Als Alternative zur Fertigkeit "Verführen" für die "typische" Fertigkeit wäre noch "Gassenwissen" möglich gewesen, was bei M5 auch "Bestechen" und "Beschatten" (in der Stadt) umfaßt. Damit ist Gassenwissen auch extrem attraktiv, wobei es beim Hintergrund "Adel" vielleicht nicht ganz so gut paßt. Ich glaube, ich gehe anfangs eher auf die vermeintliche "Damsel in Distress" als den "korrupten Politiker". Francesco di Lardo
-
Thema von Francesco di Lardo wurde von Francesco di Lardo beantwortet in M5 - Gesetze der Erschaffung und des LernensGuter Punkt! Ich werde mal den Spielleiter fragen. Sofern man bereits einen Vertrauten hat, wenn man mit dem Spruch startet, dann ist dies sicher die bessere Wahl in jeder Hinsicht im Vergleich zu "Dämonischer Zaubermacht". Francesco di Lardo
-
Für die demnächst startende M5-Runde habe ich einen Charakter zusammengewürfelt nach der "Best 6 of 9" Methode mit u.a. - In 87 - Zt 89 - pA 99 Vom Stand kam "Adel" heraus, was noch einmal 2 LE "Sozial leicht" bringt. Klang für mich nach - Hexer! Somit verfügbare LE: Mein Konzept für Level 1 ist "der soziale Manipulator", was sich wie folgt darstellt: (Wert 8+2 bedeutet Fertigkeitswert+Bonus durch Leiteigenschaft. In der PP-Spalte ist aufgezeigt, woher die LE kommen) Bei den Sprüchen sieht's so aus: (*=Spezialisierung, hier "Beherrschen", aufgewendete LE in der "Wirkung"-Spalte) Gedanke hierbei: Mit "Angst", "Anstacheln" und "Anziehen" kann man praktisch anfangs schon einiges "tun". "Macht über die Sinne" ist so ein wenig als "Multi-Tool" gedacht. "Dämonische Zaubermacht" kann die Beherrschungszauber verstärken um +2, das typische "Verwünschen" den Widerstand des Opfers um -1 Schwächen. Wenn ich dies dann noch mit "Anziehen" kombiniere und dann die Fertigkeit "Verführen" ziehe, kann sich das fürs 1. Level ziemlich akkumulieren (sofern alles klappt...) "Schreiben (Muttersprache)" hatte ich als Alltagsfertigkeit dem "Schwimmen" vorgezogen, weil man bei Erschaffung dann mit Schreiben +12 anstatt später +8 startet. Das Fehlen von "Lesen von Zauberschrift" erscheint mir eine Lücke, doch ist dies später günstig nachzulernen. Bei der "Qual der Wahl" im Rahmen des Konzepts dachte ich mir daher: Erstmal Labern - dann Lesen... Ich hatte auch in Erwägung gezogen, statt "Dämonische Zaubermacht" evtl. "Binden des Vertrauten" zu wählen, was vom "gesparten" EP-Einsatz sicher günstiger wäre. Doch ein Vertrauter will einen Monat erst einmal gebunden werden, d.h. wirkt sich für einige Zeit im Spiel noch nicht praktisch aus, wobei man gleichzeitig noch nicht viel andere Sprüche hat. Ferner war auch "Sehen in Dunkelheit" in der engeren Wahl, weil man schließlich nur das bezaubern kann, was man auch sieht (sofern man's nicht berührt oder man selbst das Ziel ist). Mit anderen Worten, in Dunkelheit oder bei Unsichtbaren steht der Hexer sonst ziemlich "blank" da. Kann aber ja sein, daß ich irgendwelche "entscheidenden" Dinge nicht beachtet habe - ist schließlich mein erster M5 Charakter. Und der letzte magiekundige M3/M4 Charakter liegt "Jahrzehnte" zurück. Feedback? Anregungen? Kritik? Francesco di Lardo

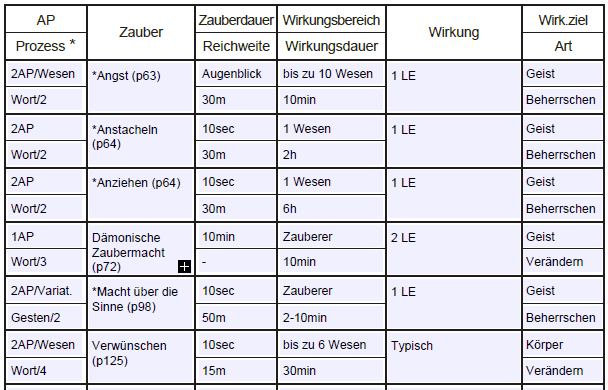

-
Ich fürchte, da hast Du Recht. Bin auch über einen anderen Thread gestolpert, in dem es um die Beurteilung der Illustrationen im Moravod-Band ging. Da sagte Branwen, man hätte für die Zahl der Illustrationen nach "konventioneller" Art sieben Zeichner benötigt, die a) nicht zur Verfügung standen und b) den Preis für den Band auf über 50 Euro gesteigert hätten. Die Alternative dazu wären die mehr "computerartigen" Illustrationen gewesen. Sie holte dann Feedback ein, um zu ergründen, welche Alternative vor diesem preislichen Unterschied bevorzugt worden wäre. Ich glaube, Moravod ist 2021 erschienen. Mit anderen Worten noch vor tauglicher generativer AI für Bilder. D.h. vermutlich haben zu dem Zeitpunkt dann noch "echte Leute" mit Photoshop o.ä. das Artwork erledigt. Aber selbst zu dem Zeitpunkt war dies preislich schon die Frage: Entweder "computerartig" oder nur 1/3 Anzahl an Illustrationen nach "klassischer Art", was vielen dann wohl auch nicht gefallen hätte. Also bereits damals eine Zwickmühle für den Publisher. Das sieht heute natürlich noch einmal ganz anders aus: Im Prinzip bekommt heute jeder Laie mit KI Bilder hin, die selbst nach den Maßstäben von nur vor ein paar Jahren "atemberaubend" sind (natürlich mit den KI - noch - eigenen Glitches). Zu diesem Urteil komme ich quasi im "Selbstversuch" - als absoluter Anfänger mit Null Erfahrung in der Sache im allerersten Versuch kam bei mir Anfang des Jahres nach einem Abend da schon Erstaunliches heraus (was sich auch irgendwo hier im Forum in einem Thread finden läßt). Wenn nun im Vergleich zu mir Leute mit KI Bilder erstellen, die sich tiefer damit befaßt haben, wird dies noch einmal eine deutliche Schippe besser sein. Und gleichzeitig machen darüber hinaus auch nur ein paar Monate Fortentwicklung der Technik einen Unterschied, die sich atemberaubend schnell vollzieht. Das ist für die "klassischen" Illustratoren, die die Fertigkeit haben, von Hand zu zeichnen, natürlich hart. Vermutlich können sie sich in einem "Hochpreissegment" eine Nische erhalten, in dem sie Leute bedienen, die "Handwerkskunst" schätzen und wollen. Ansonsten werden sie vermutlich auch auf den KI-Zug aufspringen müssen. Dabei haben sie gegenüber Laien sicherlich den Vorteil, daß sie ihr handwerkliches Wissen, wie man Bilder komponiert, wie mit Licht zu arbeiten ist usw. wohl auch im Rahmen der Arbeit mit KI einfließen lassen können. Francesco di Lardo
-
Das ist eine Sache, von der ich nichts gehört habe und daher nicht beurteilen kann. Freilich habe ich mich viele Jahre lang auch nicht im Midgard-Umfeld bewegt - und außerhalb desselben dürfte diese Frage des Rufs auch kaum Thema gewesen sein. Auch wenn viele heutzutage Foren kaum noch nutzen, sondern eher - wie soll man es nennen - "flüchtigere" Medien, wie etwa Discord, bevorzugen, mag ich sie. Sie sind m.E. nach überlegen als Ressource, Archiv, Knowledge-Base. Letztlich war dies für mich der Grund, dieses Forum als Anlaufpunkt zu suchen. In anderen Foren habe ich meine Erfahrungen gesammelt - ob nun als User im Bereich fünfstelliger Posts oder auch als Moderator. Nach etwa einem Jahr hier, sowohl als User wie auch mit Blick auf die Midgard-Szene "von außen kommend", stelle ich schon fest, daß die Atmosphäre hier eine andere ist, wie ich sie aus anderen Foren gewohnt bin: Sie ist nicht so ungezwungen. In den Umgebungen, die ich kenne, ist man souveräner dazu in der Lage, "sich darauf einigen zu können, sich nicht einig zu sein", ohne daß einem dies jemand nachzutragen scheint bzw. sich "gewisse Vibes" nicht auf nichtverwandte Threads übertragen. Nun, ich sollte vielleicht fairer Weise nicht "souveräner" sondern "besser" als Begriff verwenden - es geht schließlich um Foren... Bevor nun jemandem die Finger zu jucken beginnen, diesen Beitrag von mir als off-topic zu taggen: Was ich beschrieben habe, äußert sich meinem Eindruck nach am deutlichsten in den Ausprägungen der Damatu-Thematik. Ob dies mein abschließendes Urteil sein wird, wird die Zeit zeigen. Gleichzeitig erscheint es mir jedoch auch mehr als nur ein erster Eindruck. Francesco di Lardo
-




